



欢迎扫码观看
文章视频简介
目前,患者影像学检查需求激增程度已经远远超过了放射科医师增长数量[1⇓-3],这种失衡导致工作负荷增加、诊断发布延迟,且增高了医疗人员的职业倦怠风险[4],影响了医疗服务效率与诊疗护理质量[5]。近年来,人工智能(AI)在医学中的应用越来越广泛[6-7]。其中,生成式AI技术凭借其快速生成详细文本的能力,为影像学报告生成自动化提供了一种潜在的解决方案,有助于提高放射科医师的工作效率并减轻工作负担[8⇓-10],使他们能够专注于复杂病例和关键决策上[11-12]。
近期研究探索了生成式AI在影像学报告生成方面的潜力,但结果不一,引发了争议。Sun等[13]评估了GPT-4在生成50份胸部X线报告方面的表现,认为AI生成的结论不如放射科医师。然而这一结论受到了Ray[14]的质疑,他们强调了AI的潜力和进一步研究的必要性。其他研究显示AI在辅助医学文本生成方面有积极的成果,例如用于影像学报告的迭代优化框架提示了放射科医师与AI协作改善报告质量的好处[15],而使用预训练变换器自动生成放射学报告的初步评估为AI在这一领域的潜力提供了早期证据[16]。尽管取得了这些进展,但现有研究仍受限于样本量小、缺乏放射学专家的全面评估以及简化的提示可能无法充分利用AI的能力。此外,一些研究过度依赖自动化指标而非放射科医师的评估[15,17],可能忽视了临床实用性和可解释性的关键方面[18-19]。
本研究评估了生成式AI ERNIE 4.0和Claude 3.5 Sonnet在影像学报告生成方面的表现,通过扩大样本量并将研究范围扩大到更复杂的腹部CT和MRI检查以解决前期研究的局限性。并且在采用了模拟放射科医师诊断过程的高级提示工程技术的基础上,进一步由专业放射科医师对模型进行评估。这些改进有助于更全面地探讨生成式AI在影像学报告生成方面的能力。现将研究结果报告如下,以期为同行们进一步合理应用生成式AI生成影像学报告提供参考。
1 对象与方法
1.1 研究对象
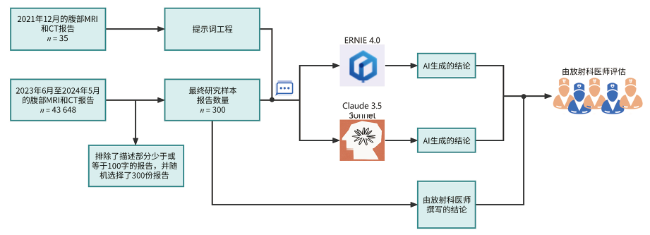
本研究回顾性收集2023年6月至2024年5月在我院进行腹部CT或MRI检查的患者的影像学报告。初步纳入该期间的所有腹部CT和MRI报告(共43 648份)。在排除了影像所见部分少于100字的报告后,从剩余报告中随机选取300例独立患者的300份报告进行分析(筛选报告时仅选择“检查部位”字段含有“上腹部”“下腹部”或“盆腔”的病例,涵盖广泛的疾病类型,不限于典型特征)。详细的数据选择过程代码已公开发表在GitHub平台(https://github.com/lichao312214129/code_for_impressionGeneration)。随机数据选择程序在’random_data_selection.py’脚本中实现。除上述300份报告外,本研究还纳入了2021年12月的35份CT和MRI报告,专门用于提示工程,以指导生成式AI基于影像学检查结果生成结论。在每份报告中,所有受检对象的个人健康信息和潜在可识别数据均被删除。研究设计见图1。本研究获得我院伦理委员会的批准(批件号:中大附三医伦Ⅱ2023-042-01),并因使用非身份识别数据而豁免了知情同意。
1.2 生成式AI的选择
于2024年6月13日至7月5日期间访问ERNIE 4.0(ERNIE-4.0-8K-Latest, https://qianfan.cloud.baidu.com)和Claude 3.5 Sonnet(claude-3-5-sonnet-20240620, http://claude.ai)。选用这2个模型是基于它们在生成式AI领域的领先地位和广泛认可度。ERNIE 4.0在本研究进行时被认为是中国先进的大型语言模型之一;Claude 3.5 Sonnet在本研究进行时代表了美国生成式AI的前沿,在多个方面超越了GPT-4。选用这2个模型旨在比较中美两国在生成式AI领域的最新技术进展,并在放射学报告生成的具体应用场景中评估它们的性能差异。
本研究使用Python 3.8.16脚本和OpenAI 1.33.0 包与ERNIE 4.0和Claude 3.5 Sonnet的应用程序编程接口(application programming interface,API)进行交互。将所有模型的温度参数设置为1×10-10以限制随机性[20]。考虑到单次输出的令牌长度限制,对每个案例进行了多次对话迭代,以确保生成完整和连贯的影像学结论。用于此过程的代码已公开发布在GitHub平台(https://github.com/lichao312214129/code_for_generating_impression)。使用正则表达式从AI模型的输出中提取影像学结论。
1.3 提示工程
受近期关于如何创建优秀放射学报告建议研究的启发[21],对初始提示实施了逐步优化提示以提高质量和透明度。这种思维链方法模拟了放射科医师的推理过程,通过结构化分析引导AI。迭代过程涉及每个案例的多次对话,并在每一步进行人工验证以确保内容的完整性、准确性和连贯性。所有提示采用中文以匹配中国放射科医师的临床环境和患者的目标受众。通过反复优化提示结构和语言(例如开始时可能只是1个简单的指令,如“根据报告的描述部分生成报告的结论部分”,发现效果不佳后改为“逐一列出描述中的所有异常,然后结合所有异常生成相应的影像学结论”),使生成式AI生成的影像学结论的质量和可靠性得到显著提高,为后续比较分析提供坚实基础。
1.4 性能评估
由5名放射科医师(3名分别具有17年、9年、9年工作经验的中级医师及2名具有4年工作经验的初级医师)对纳入研究的300份影像学报告(每一份中均包含生成式AI与放射科医师的结论)进行独立评估。为确保评估的一致性,对5名评估者进行了校准练习:随机选择5个案例,评估者分别对其进行独立评估,然后开会讨论结果并形成统一标准。这一过程旨在正式评估前提高评估者间的一致性。
本研究分析了300份影像学报告,将其随机分为2个子集:子集1包含250份报告,子集2包含50份报告。将子集1随机分配给5名评估者,每名评估者独立评估50份报告。将子集2分配给所有评估者进行重复评估,即5名评估者均对子集2的50份报告进行独立评估。这一设计旨在测量评估者之间的一致性。在评估过程中,对除影像学报告外的其他临床数据进行盲法处理。为比较生成式AI和放射科医师的表现,将子集1(250份报告)的评估数据与年资最高的评估者对子集2(50份报告)的评估数据整合在一起,创建一个包含300份报告的综合数据集用于进一步分析。这种一致性分析方法在以往文献中已有相关报道[22]。
为减少偏倚,每份影像学报告 (无论是生成式AI的结论还是放射科医师的结论)均被分配由7个随机字符串构成的唯一标识符。对于每个案例,ERNIE 4.0、Claude 3.5 Sonnet和放射科医师的结论的顺序被随机化,以防止任何与顺序相关的评估偏倚。报告以随机顺序呈现的方式在以往的研究中已有报道[20]。
评估采用五点Likert量表(1表示强烈不同意,5表示强烈同意),重点关注5个关键标准:完整性、幻觉、准确性、表达和无修改接受度,每个指标的详细评分标准已公开发布在GitHub平台( https://github.com/lichao312214129/code_for_generating_impression)。这种评估方法参考了既往研究中的实践经验[23]。
1.5 统计学方法
所有统计分析使用Python 3.8.16、SciPy 1.10.1、Scikit-posthocs 0.8.1和Statsmodels 0.13.5进行[24]。对连续变量(如年龄和报告字数)采用M(P25,P75)描述,对分类变量(如性别、患者来源、检查方式、增强情况和检查部位)采用n(%)描述,以全面概括300例研究对象的基本特征分布。由于某些标准(如幻觉)的评分分布极端,大多数案例被5名评估者一致评为1,常规的评估者间一致性测量标准(如Fleiss’ Kappa系数)不适用,因此,对于每项评估标准(完整性、幻觉、准确性、表达和无修改接受度)进行评估者间评分一致性的占比计算,一致性被定义为3个层级:完全一致(5位评估者给出相同评分),高度一致(4位评估者给出相同评分)和基本一致(3位评估者给出相同评分),比较采用χ 2检验。
采用Friedman检验比较ERNIE 4.0、Claude 3.5 Sonnet和放射科医师在5个评估标准上的表现。使用Nemenyi检验进行事后成对比较(每项评估标准评分采用$\bar{x} \pm s$表示)。采用双侧检验,P < 0.05为差异有统计学意义。为确保可重复性,所有用于数据分析和可视化的代码同样公开发布在GitHub平台( https://github.com/lichao312214129/code_for_generating_impression)。
2 结果
2.1 一般资料
本研究分析了300例患者的300份CT和MRI报告,300例患者以中年男性为主,检查部位以上腹部为主,主要来源于住院部和门诊。报告包括164份CT扫描和136份MRI扫描,其中253份为增强检查。影像学所见部分描述的字数中位数为320字。患者一般资料见表1。
表1 300例接受CT和MRI检查患者的一般资料Table 1 General information of 300 patients receiving CT and MRI examinations |
| 项 目 | 数值 |
|---|---|
| 性别/n(%) | |
| 男 | 202(67.3) |
| 女 | 98(32.7) |
| 年龄a/岁 | 52.0(40.0,62.0) |
| 患者来源/n(%) | |
| 急诊 | 28(9.3) |
| 住院 | 139(46.3) |
| 门诊 | 133(44.3) |
| 检查方式/n(%) | |
| CT | 164(54.7) |
| MR | 136(45.3) |
| 增强检查/n(%) | |
| 对比增强 | 253(84.3) |
| 无对比增强 | 47(15.7) |
| 检查部位/n(%) | |
| 上腹部 | 238(79.3) |
| 中+下腹部 | 33(11.0) |
| 下腹部 | 26(8.7) |
| 中腹部 | 1(0.3) |
| 上+中腹部 | 1(0.3) |
| 上+中+下腹部 | 1(0.3) |
| 影像学报告字数 | 320(255,403) |
注:a1例患者的年龄数据缺失。 |
2.2 5名评估者之间的一致性
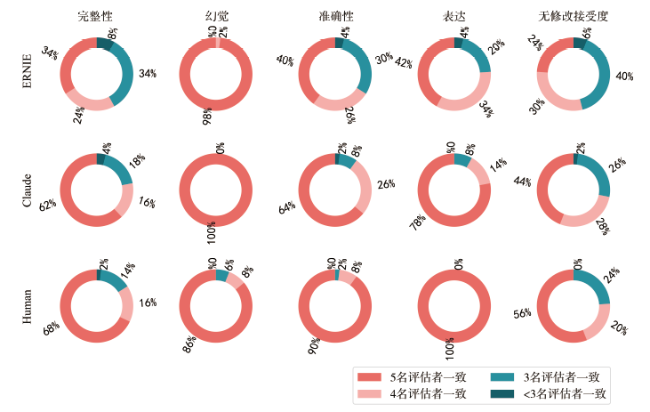
所有评估标准显示评估者间一致性均较高,见图2。对于ERNIE 4.0生成的结论,至少3/5的评估者评分一致的占比情况:完整性(92.0%),幻觉(100%),准确性(96.0%),表达(96.0%),无修改接受度(94.0%)。对于Claude 3.5 Sonnet生成的结论,至少3/5的评估者评分一致的占比情况:完整性(96.0%),幻觉(100%),准确性(98.0%),表达(100%),无修改接受度(98.0%)。对于放射科医师的结论,至少3/5的评估者评分一致的占比情况:完整性(98.0%),幻觉(100%),准确性(100%),表达(100%),无修改接受度(100%)。ERNIE 4.0、Claude 3.5 Sonnet和放射科医师在完整性(χ 2 = 12.59,P < 0.01)、幻觉(χ 2 =12.59,P < 0.01)、准确性(χ 2 = 12.24,P < 0.01)、表达(χ 2 = 24.32,P < 0.01)和无修改接受度(χ 2 = 21.58,P < 0.01)5个指标比较差异均有统计学意义。
2.3 性能比较
Nemenyi检验显示,在完整性和无修改接受度方面,ERNIE 4.0的得分低于Claude 3.5 Sonnet和放射科医师(P均 = 0.001),后两者之间比较差异无统计学意义(P均> 0.05)。在准确性方面,放射科医师优于ERNIE 4.0和Claude 3.5 Sonnet(P均=0.001)。在幻觉和表达方面,3组表现相似,比较差异均无统计学意义(P均> 0.05),见图3。
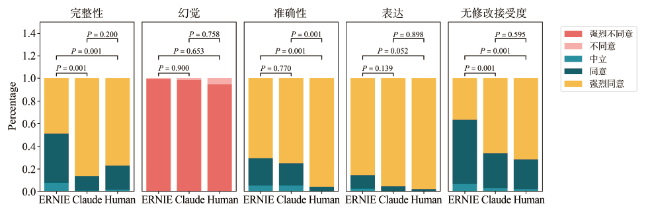
总体而言,Claude 3.5 Sonnet在多个方面的表现与放射科医师相当,而ERNIE 4.0在某些领域仍有改进空间。Friedman检验显示幻觉在3组间的差异具有统计学意义,但进一步采用Nemenyi检验进行两两比较,并未发现任意2组间的差异具有统计学意义,这可能是由于大多数幻觉得分为1、分布高度偏斜所致。生成式AI与放射科医师在影像学报告生成任务中的表现见表2。
表2 AI模型与放射科医师在医学影像报告生成任务中的表现比较 单位:分Table 2 Comparison of AI models and radiologists, performance in medical image report generation tasks |
| 指 标 | ERNIE 4.0 | Claude 3.5 Sonnet | 放射科医师 |
|---|---|---|---|
| 完整性 | 4.40±0.64 | 4.86±0.37 | 4.76±0.46 |
| 幻觉性 | 1.01±0.08 | 1.02±0.13 | 1.05±0.23 |
| 准确性 | 4.66±0.57 | 4.69±0.57 | 4.96±0.22 |
| 表达力 | 4.82±0.48 | 4.96±0.20 | 4.98±0.14 |
| 修改度 | 4.30±0.59 | 4.64±0.53 | 4.69±0.54 |
本研究发现人类医师生成的影像学报告也存在“幻觉”现象,即影像学结论包含了影像学所见中未描述的内容。这主要源于放射科报告的审核流程:资深医师在审核初级医师的报告时,可能发现初级医师遗漏的重要病变,但出于对工作效率的考虑,资深医师往往在影像学结论部分直接添加这些内容,而未更新影像学所见部分,导致两者出现不一致的情况。
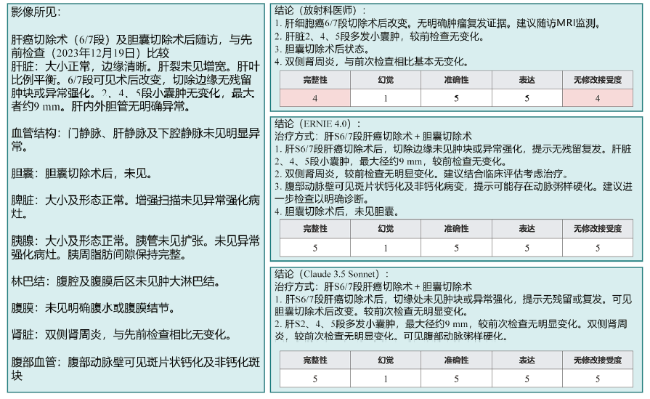
图4 ERNIE 4.0、Claude 3.5 Sonnet和放射科医师的影像学报告案例一注:左图为影像报告的影像学所见部分。右图包括3个子图,第1个子图显示放射科医师的结论,其中遗漏了主动脉粥样硬化的诊断;第2个子图显示ERNIE 4.0生成的结论,包括所有相关发现,如主动脉粥样硬化;第3个子图显示Claude 3.5 Sonnet生成的结论,同样包括所有相关发现。 Figure 4 ERNIE 4.0, Claude 3.5 Sonnet and radiologist imaging report Case 1 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
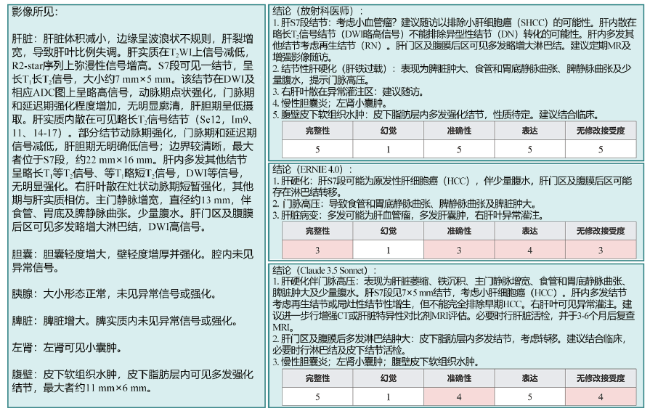
图5 ERNIE 4.0、Claude 3.5 Sonnet和放射科医师的影像学报告案例二注:左图显示影像学报告的影像学所见部分。右图包括3个子图,第1个子图显示放射科医师的结论;第2个子图显示ERNIE 4.0生成的结论,其中遗漏了关键诊断,如慢性胆囊炎、左肾囊肿、腹壁皮下软组织水肿和皮下脂肪层多发强化结节,此外还将肝血管瘤误诊为肝细胞癌,将肝硬化结节误诊为多发血管瘤;第3个子图显示Claude 3.5 Sonnet生成的结论,虽然也将肝S7段的血管瘤误诊为肝细胞癌,但准确包含了其他相关发现。 Figure 5 ERNIE 4.0, Claude 3.5 Sonnet and radiologist imaging report Case 2 |
3 讨论
本研究比较了2种先进的生成式AI在生成腹部CT和MRI影像学报告方面的表现,并与放射科医师进行比较。结果表明,Claude 3.5 Sonnet在多个方面达到了与放射科医师相当的水平,而ERNIE 4.0则显示出有改进空间,尤其是在完整性和无修改接受度方面,ERNIE 4.0的表现劣于Claude 3.5 Sonnet。三者在表达和幻觉方面表现相似。然而在准确性方面,放射科医师优于Claude 3.5 Sonnet和ERNIE 4.0。上述结果表明了Claude 3.5 Sonnet在生成影像学报告方面具有较强能力,同时也表明当前由生成式AI生成影像学报告应在放射科医师的监督下完成。
本研究存在一定局限性。首先,作为单中心研究,本研究结果的泛化性可能有限,需要多中心研究来验证这些结果在不同临床环境中的适用性。其次,本研究专注于腹部影像学报告,可能无法反映AI在其他检查部位的表现,未来的研究应扩展至更全面的人体检查部位。第三,虽然本研究的评估标准较全面,但开发更细化的指标可能更有助于对AI模型在特定临床环境中的表现进行深入分析。最后,未来应开展纵向研究,以评估AI模型在临床实践中的整合对放射科医师诊断的准确性、工作效率以及患者临床结局的长期影响。
本研究结果表明,生成式AI在放射学工作流程中展现出显著潜力,有望成为一种有价值的辅助工具。本研究也揭示了一些需要进一步优化和改进的部分。随着AI技术的持续发展,将其有效整合到放射学临床实践中可能会显著提升工作效率,并有望改善患者的管理质量。未来在放射学领域融入AI模型时,应着重关注放射科医师与AI模型协作模式的构建,而非单纯追求技术替代。这种协作应充分发挥AI的计算能力和放射科医师的临床经验,以此优化诊断流程,提高整体诊断的准确性和效率。此外,还需要进行更多的前瞻性研究,以评估AI技术辅助诊断在实际临床环境中的长期效果和影响。